Reklaam
27. jaanuaril teatas Google, et AlphaGo, an tehisintellekt Mis tehisintellekt poleKas intelligentsed, tundlikud robotid hakkavad maailma üle võtma? Mitte täna - ja võib-olla mitte kunagi. Loe rohkem Selle tütarettevõtte DeepMind välja töötatud meeskond oli viiest mängust alistanud Euroopa Go meistri Fan Hui.
Võib-olla olete sellest uudisest kuulnud, kuna see teeb pealkirju kogu maailmas, kuid miks inimesed sellest nii väga hoolivad? Mida see kõik tähendab? Kui te ei tunne mängu Go või selle olulisust tehisintellekti jaoks, võite end pisut eksida.
Ärge muretsege, oleme teiega kaetud. Siin on kõik, mida peate teadma läbimurde ja selle kohta, kuidas see mõjutab tavalisi inimesi nagu sina ja mina.
Mängukäik: Lihtne, kuid siiski keeruline
Go on iidne Hiina strateegiamäng, kus kaks mängijat võitlevad territooriumi hõivamiseks. Kordamööda asetab iga mängija - üks valge, teine must - kivid 19 x 19 ruudustiku ristumiskohtadele. Kui rühm kive on teise mängija kividega täielikult ümbritsetud, siis nad "hõivatakse" ja eemaldatakse laualt.
Mängu lõpus kuulub iga tühi koht ümbritsevale mängijale. Iga mängija skoor põhineb sellel, kui palju territooriumi ta omab (st kui palju tühja ruumi ta on ümbritsenud) pluss vastaste tükkide arvu, mis mängu ajal tabati.

Ehkki enamik inimesi arvab malest kui strateegiamängude kuningast, on Go tegelikult keerulisem. Vikipeedia andmetel on neid 10761 võimalikud Go mängud võrreldes 10-ga120 hinnangulised malemängud.
See keerukus koos mõnede esoteeriliste reeglite ja rõhuasetusega instinkti mängimisele teeb Go-ist arvutite jaoks eriti raskeks mänguks, et seda kõrgel tasemel õppida ja mängida.
Mänguautomaatide uskumatu maailm
Asjade suures plaanis ei tundu mängu mängiv tehisintellekti kavandamine eriti väärt jälitamine, eriti kui IBMi Watson AI töötab juba tervishoiu parandamise nimel - valdkond, mis vajab kogu võimalikku abi saada. Miks kulutas Google nii palju tunde ja dollareid, et luua Go-playing AI?
Ühel tasandil aitab see AI teadlastel välja mõelda parim viis arvutite õpetamiseks. Kui saate õpetada arvutit otsustama, kuidas kabe või Tic-Tac-Toe mängus parimaid käike leida, võiksite saada ülevaate teise arvuti õpetamisest, kuidas soovitage filme Netflixis 4 masinaõppe algoritmid, mis kujundavad teie eluTe ei pruugi seda mõista, kuid masinõpe on juba teie ümber ja see võib teie elule üllatavalt palju mõju avaldada. Ei usu mind? Võite olla üllatunud. Loe rohkem , tõlkida koheselt kõnet või ennustada maavärinaid.
Paljudele AI-de kasutamistele, mida me seni oleme näinud, tuleks kasu parematest probleemide lahendamise ja mustrite eraldamise võimalustest, mis on samuti olulised mängude mängimiseks mõeldud AI-de jaoks.
Male meister AI Deep Blue töötas kõigi võimalike järgmiste käikude hindamiseks tohutu arvutusjõu ja jõhkra jõu tehnikaid kasutades - kuni 200 000 000 positsiooni sekundis. Ja kuigi see strateegia oli piisavalt efektiivne, et lüüa endine maailmameister, pole see male mängimiseks eriti “inimlaadne” viis. See nõuab ka programmeerijatelt AI-le mängureeglite “selgitamist”.
Hiljuti töötati välja protsess nimega sügav õppimine, mis sisuliselt sillutas teed arvutitele enese õpetamiseks, ja see muutis täielikult võistlus tehisintellekti pärast Microsoft vs Google - kes juhib tehisintellekti võistlust?Tehisintellekti uurijad teevad käegakatsutavaid edusamme ja inimesed hakkavad taas AI-st tõsiselt rääkima. Kaks tehisintellekti võistlust juhtivat titaani on Google ja Microsoft. Loe rohkem .
Sügava õppimise abil saab arvuti kaevandada andmetest kasulikke mustreid - selle asemel, et programmeerijad neile öelda, milliseid mustreid ta peaks otsima - ja kasutada neid mustreid oma otsuste optimeerimiseks. Kui sügav õppimine on edukas, saab AI avastada isegi tõhusamaid mustreid kui need, mida suudame inimesena ära tunda.
Seda tüüpi õppimist demonstreeriti eelmisel aastal, kui Google'ile kuuluv AI uuringufirma DeepMind avalikustas AI, mis õpetas ennast mängima 49 erinevat Atari mängud Atari arcade - mängige HTML5-s retro-videomänge [MUO Gaming]Igaüks, kes täna videomänge mängib, võlgneb Atari ning asutajate ja inseneride tohutu tänuvõla, kes töötasid ettevõtte heaks selle kujunemisaastail. Atari oli vastutav paljude ... Loe rohkem pärast seda, kui talle on antud ainult toores sisend. (Näete seda Breakouti mängimist õppimas.)
Protsess on sama, mis videomängu õppimine ilma juhendaja või selgituseta. Vaatad mõnda aega, proovid siis vajutada juhuslikke nuppe, siis hakkad asju välja mõtlema, strateegiaid välja töötama ja lähed lõpuks silma paista.
Ja suurepäraselt see ka õnnestus. DeepMind AI hävitas mõnedes sellistes mängudes, nagu näiteks Video Pinball, absoluutselt professionaalse taseme vastased. Teistes mängudes, sealhulgas pr. Pac-Manis, õnnestus see märkimisväärselt halvemini, kuid tema rekord oli üldiselt väga muljetavaldav.
AlphaGo: AI järgmine tase
Fan Hui at Go'is alistanud arvuti AlphaGo kasutas seda sügava õppimise strateegiat viies matšis võitmatuks.
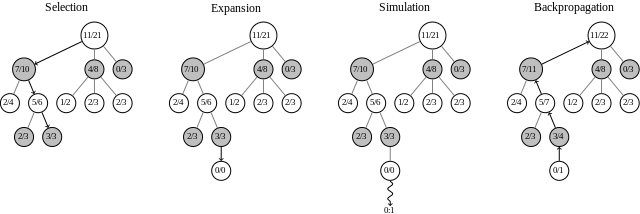
Selle asemel, et kasutada jõhkra jõu arvutamist nagu Deep Blue, määras AlphaGo järgmise sammu, kasutades treenimisel õpitu piirake potentsiaalselt efektiivsete käikude ulatust, seejärel käivitage simulatsioonid, et näha, millised käigud olid kõige tõenäolisemalt positiivsed tulemusi.
Kaks erinevat närvivõrgud Viimane arvutitehnoloogia, mida peate uskumaVaadake mõnda uusimat arvutitehnoloogiat, mis on lähiaastatel muudetud elektroonika ja personaalarvutite maailma muutmiseks. Loe rohkem , poliitikavõrgustik ja väärtusvõrgustik töötasid kokku, et hinnata käike ja valida iga pöörde jaoks parim.
Go keerukuse tõttu pole julma jõu lähenemine kõigile võimalikele käikudele lihtsalt võimalik, nagu see on malevas. Nii kasutas AlphaGo teadmisi, mille ta sai koolitusfaasis, mis koosnes 30 miljoni liigutuse jälgimisest inimeksperdid, õpivad oma käike ette ennustama, tulevad välja oma strateegiatega ja mängivad enda vastu tuhandeid korda.
Tugevdusõppe abil arendati ja tugevdati selle otsustusprotsesse, kuni AlphaGo-st sai maailma parim Go-playing AI. 500 mängus kõige arenenumate Go-arvutite vastu võitis ta neist 499 - isegi pärast neile programmidele neljakäigulise pealae andmist.
Ja muidugi alistas AlphaGo praeguse Euroopa Go meistri Fan Hui. Võit saavutati tegelikult 2015. aasta oktoobris, kuid teadaande edasilükkamine langes kokku DeepMindi uurimistöö avaldamisega Loodus. Märtsis astub AlphaGo üles viimase kümne aasta jooksul maailma domineerivaim mängija Lee Sedol.
Olgu, mida see kõik tähendab?
Miks see teeb pealkirju kogu maailmas? Tegelikult mitmel põhjusel.
Esiteks arvasid paljud inimesed, et praeguse tehnoloogiaga on see võimatu. Enamiku hinnangute kohaselt ei lööks AI vähemalt kümme aastat maailmatasemel Go-mängijat. AlphaGo väärtusvõrgustikud saavad hinnata kõiki praegu mängitavaid Go-mänge ja ennustada potentsiaalset võitjat - see probleem on Google'i sõnul „nii raske see oli arvatakse olevat võimatu. ”

Teiseks on väga oluline asjaolu, et kasutati sügavat ja iseseisvat õpet. See näitab, et praegune tehisintellekt suudab andmeid koguda, mustreid välja õppida, õppida neid ennustama mustrid ja arendavad lõpuks välja probleemide lahendamise strateegiad, mis on piisavalt keerulised ja tõhusad, et a maailmatasemel inimene.
Ja kuigi Go-ga võitmine ei muuda maailma, on tõsiasi, et arvuti suutis omaenda õppealgoritmide abil sellise tasemega strateegia välja mõelda.
Just see sügav õppimine on AI teadlased AlphaGo-st tõeliselt vaimustuses. Paljud usuvad, et iseseisev õppimine on esimene samm a tugev tehisintellekt. Tugev AI viitab arvutile, mis suudab lahendada intellektuaalseid ülesandeid võrdselt inimestega (mis on uskumatult keeruline, suuresti inimese aju keerukuse ja tõhususe tõttu). Seda tüüpi AI-d näete palju ulmefilme Tähelepanu, Internet! Parimad filmid tehisintellekti kohtaHollywood on aastate jooksul välja andnud palju suurepäraseid filme, mis uurivad tehisintellekti teemasid. Siin on 10 parimat filmi AI kohta, soovitame kolida Taevas ja Maa ... Loe rohkem .

Just sel põhjusel on inimmõistetavalt käituvate AI-de loomine nii suur asi. Mustrite kaevandamine ja strateegiate väljatöötamine on midagi, mida teeme pidevalt ja me ei kasuta otsuste tegemisel julma jõu meetodeid.
On väga keeruline hankida arvutit, kus seda ilma palju juhendamata teha saaks, kuid tänu AlphaGole teame nüüd, et tugev AI pole lihtsalt võimalik, vaid lähemal kui me arvasime.
Muidugi on Go-playing AI kaugel üldiselt intelligentsest AI-st. See teeb ainult ühte, mis on nii lihtne kui tehisintellekti saada - isegi Atari mängiv AI oli võimeline mängima 49 erinevat mängu Tulevased videomängude AI-d võidavad teid tõsiseltVideomängude AI pole veel nii suurepärane - veel pole. Hiljutise tehnoloogia arenguga võib see aga peagi muutuda. Loe rohkem - kuid AlphaGo tõhus iseseisev õppimine võiks olla esimene samm AI suurema paradigma muutuse suunas.
Mida sa arvad?
Pole kahtlust, et AlphaGo võit Fan Hui üle on oluline, kuid selle üle, kas see väärib ülemaailmseid pealkirju, tuleb arutleda.
Kas sa arvad, et see on suur asi? Kas oleme sammu lähemale? roboti apokalüpsis Microsoft, tehisintellekt ja roboti apokalüpsisMicrosoft pöörab reale autonoomsetele robotitele tõsist pilku. Kas see on inimeste jaoks lõpu algus või on see veel üks samm ohutu tehisintellekti poole püüdlemisel? Loe rohkem ? Või ei avalda teile muljet AI, mis võib lihtsalt mängu mängida? Jagage oma mõtteid allpool ja räägime sellest.
Pildikrediidid: mine mängu saatis Shvorstocki kaudu vvoe, Tatjana Belova saidi Shutterstock.com kaudu, Mciura Wikimedia Commonsi kaudu, Zerbor saidi Shutterstock.com kaudu
Dann on sisestrateegia ja turunduskonsultant, kes aitab ettevõtetel nõudlust tekitada ja viib. Samuti ajaveeb ta veebiaadressil dannalbright.com strateegia- ja sisuturunduse kohta.

