Reklaam
Kas usute ideesse, et kui midagi Internetis avaldatakse, avaldatakse see igavesti? Noh, täna hajutame selle müüdi.
Tõde on see, et paljudel juhtudel on teabe kustutamine Internetist täiesti võimalik. Muidugi, seal on rekord veebilehti, mis on kustutatud, kui te otsite Tagasitee masin, eks? Jah, absoluutselt. Wayback Machine'is on paljude aastate taha ulatuvate veebilehtede andmed - lehed, mida te Google'i otsinguga ei leia, kuna seda lehte enam pole. Keegi kustutas selle või veebisait suleti.
Niisiis, sellest ei saa mööda, eks? Teave graveeritakse igaveseks Interneti-kivisse, mida põlvkondade kaupa näha? Noh, mitte täpselt.
Tõde on see, et kuigi ühelt uudiste veebisaidilt või ajaveebist teisele levinud olulisi uudislugusid võib olla keeruline või võimatu viiruseks kustutada, tegelikult on üsna lihtne kustutada veebisait või mitu veebilehte kõigist olemasolevatest dokumentidest - eemaldada see leht nii otsingumootorite kui ka Tagasitee masin Uus tagasitee seade võimaldab teil visuaalselt Interneti-ajas tagasi reisida Näib, et alates Wayback Machinei turuletoomisest 2001. aastal on saidiomanikud otsustanud Alexa-põhise taustapildi välja visata ja selle oma avatud lähtekoodiga ümber kujundada. Pärast katsete läbiviimist ... Loe rohkem . Muidugi on saak olemas, kuid selleni jõuame.
3 võimalust ajaveebilehtede eemaldamiseks netist
Esimene meetod on selline, mida enamik veebisaitide omanikke kasutab, kuna nad ei tea midagi paremat - lihtsalt veebilehtede kustutamine. See võib juhtuda seetõttu, et olete aru saanud, et teie saidil on sisu duplikaate, või seetõttu, et teil on leht, mida te ei soovi otsingutulemustes kuvada.
Lihtsalt kustutage leht
Lehtede täieliku kustutamisega oma veebisaidil on see, et kuna olete selle lehe juba loonud netis, leidub tõenäoliselt linke teie enda saidilt, samuti väliseid linke teistelt saitidelt sellele konkreetsele saidile lehel. Selle kustutamisel tuvastab Google teie lehe kohe puuduva lehena.
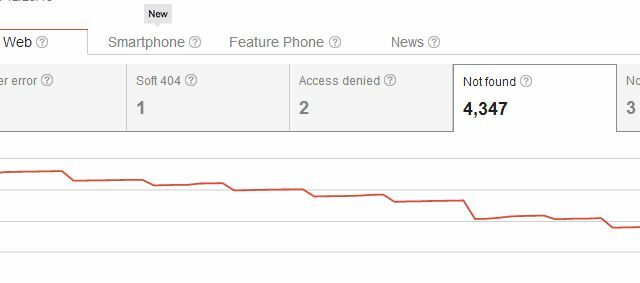
Nii et olete oma lehe kustutamisel loonud probleemiks mitte ainult enda otsimisvigade „Ei leitud”, vaid ka probleemide tekitamise kõigile, kes selle lehega kunagi linginud on. Tavaliselt näevad kasutajad, kes pääsevad teie saidile ühelt nendest välistest linkidest, teie lehte 404, mis pole a suur probleem, kui kasutate kasutajatele kasulike soovituste andmiseks midagi sellist nagu Google'i kohandatud kood 404 alternatiivid. Kuid kas te arvate, et leidub rohkem graatsilisi viise lehtede kustutamiseks otsingutulemustes, ilma et need 404-d olemasolevate sissetulevate linkide jaoks ära lüüa, eks?
No on olemas.
Lehe eemaldamine Google'i otsingutulemustes
Esiteks peaksite mõistma, et kui veebisait, mille soovite Google'i otsingutulemustes eemaldada, ei ole teie oma saidi leht, siis pole teil õnne, välja arvatud juhul, kui selleks on õiguslikud põhjused või kui sait on postitanud teie isikliku teabe võrgus ilma teieta luba. Kui see on nii, siis kasutage Google'i eemaldamise vealeidja esitada taotlus lehe eemaldamiseks otsingutulemustes. Kui teil on sobiv juhtum, võib leht eemaldatud olla teatud eduga - muidugi võib teil olla veelgi suurem edu just veebisaidi omanikuga ühenduse võtmine Kuidas Internetist vale isiklikku teavet eemaldadaVeebipõhine privaatsus pole enam tagatud. Siit saate teada, kuidas veebisaidist teatada ja Internetist isiklikku teavet eemaldada. Loe rohkem nagu ma 2009. aastal kirjeldasin, kuidas seda teha.
Kui leht, mille soovite otsingutulemustest eemaldada, asub teie enda saidil, on teil õnne. Kõik, mida peate tegema, on luua a robots.txt faili ja veenduge, et olete keelanud kas konkreetse lehe, mida te otsingutulemustes ei soovi, või kogu kataloogi koos sisuga, mida te ei soovi indekseerida. Siit saate teada, kuidas ühe lehe blokeerimine välja näeb.
Kasutaja agent: * Keela: / minu- kustutatud-artikkel-tätte--vajalik-eemaldatud.html
Võite blokeerida robotid saidi tervete kataloogide indekseerimisega järgmiselt.
Kasutaja agent: * Keela: / sisu-umbes-isiklikud asjad /
Google on suurepärane tugileht mis aitab teil luua faili robots.txt, kui te pole seda kunagi varem loonud. See toimib eriti hästi, nagu ma hiljuti artiklis kirjeldasin sündikatsioonitehingute struktureerimine Kuidas pidada läbirääkimisi sündikaatpakkumiste üle ja kuidas kaitsta teie otsingutulemusiSündikaat on tänapäeval kogu raev. Kuid äkki võite leida, et sündikaatpartner on teie algselt kirjutatud loo otsingutulemustes kõrgem kui teie! Kaitske oma otsingu paremusjärjestust. Loe rohkem nii et nad ei tee teile haiget (paludes sündikatsioonipartneritel keelata nende lehtede indekseerimine, kus teid sündikaadina müüakse). Kui mu enda sündikaatpartner sellega nõustus, kadusid mu ajaveebi dubleeritud sisuga lehed otsingukirjetest täielikult.
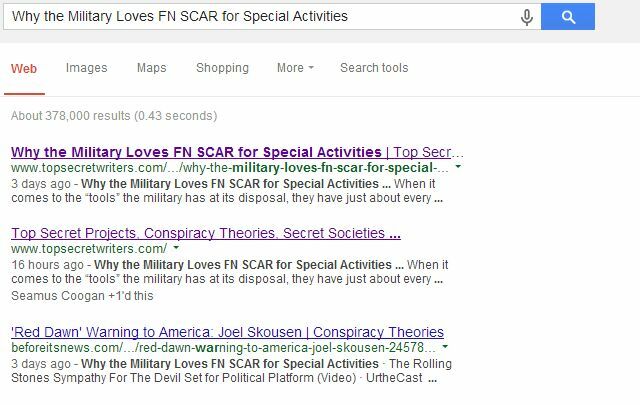
Ainult peamine veebisait kerkib selle lehe kolmandal kohal, kus nad loetlevad meie pealkirja, kuid minu ajaveebi on nüüd kirjas nii esimeses kui ka teises kohas; midagi, mis oleks olnud peaaegu võimatu, kui kõrgema asutuse veebisaidil oleks kopeeritud leht indekseeritud.
Paljud inimesed ei taipa, et seda on võimalik saavutada ka Interneti-arhiivi (Wayback Machine) abil. Siin on read, mida peate faili robots.txt lisama, et see toimiks.
Kasutajaagent: ia_archiver. Keela: / proovi kategooria /
Selles näites ütlen Interneti-arhiivile, et ta eemaldaks Wayback Machineilt kõik minu saidi näidiskategooria alamkataloogi. Interneti-arhiiv selgitab nende välistamise abilehel, kuidas seda teha. Samuti selgitavad nad, et "Interneti-arhiiv pole huvitatud juurdepääsu pakkumisest veebisaitidele või muudele Interneti-dokumentidele, mille autorid ei soovi, et nende materjalid kogumikku oleksid."
See on vastuolus üldlevinud arvamusega, et kõik Internetti postitatud andmed punnitakse kogu igaviku arhiivi. Ei - sisu omavad veebimeistrid saavad robots.txt-lähenemise abil selle sisu spetsiaalselt arhiivist eemaldada.
Eemaldage individuaalne leht metakoodidega
Kui teil on ainult mõned üksikud lehed, mille soovite Google'i otsingutulemustest eemaldada, ei pea te tegelikult kasutama robots.txt-lähenemist üldse võite lihtsalt lisada üksikutele lehtedele õige „robotite” meta-sildi ja käskida robotitel mitte kogu ulatuses indekseerida ega linke jälgida lehel.

Võite robotite lehe indekseerimise peatamiseks kasutada ülalolevat „robotite” meta-teavet või Google'i robotit mitte indekseerida, nii et leht eemaldatakse ainult Google'i otsingutulemustes ja teised otsingurobotid saaksid sellele lehele ikkagi juurde pääseda sisu.
See on täielikult teie otsustada, kuidas soovite hallata, mida robotid selle lehega teevad ja kas leht loetletakse või mitte. Vaid mõne üksiku lehe puhul on see parem lähenemisviis. Terve sisukataloogi eemaldamiseks kasutage meetodit robots.txt.
Sisu eemaldamise idee
See keerab pea kogu mõiste "Internetist sisu kustutamine" pea peale. Tehniliselt kui eemaldate kõik oma saidil olevad lingid ja eemaldate selle Google'i otsingust ja Interneti-arhiiv, kasutades robotit.txt tehnikat, on see leht kõikidest eesmärkidest ja eesmärkidest Internetist kustutatud. Lahe on aga see, et kui lehele on olemas lingid, siis need lingid ikkagi töötavad ja te ei kutsu nendele külastajatele 404 viga.
See on „õrnem” lähenemine sisu eemaldamiseks Internetist, ilma et teie veebisaidi olemasolev linkide populaarsus kogu Internetis segadust tekitaks. Lõppkokkuvõttes on teie otsustada, kuidas hallata seda sisu, mida otsimootorid ja Interneti-arhiiv kogub, kuid alati pidage meeles, et hoolimata sellest, mida inimesed räägivad veebis postitatavate asjade eluea kohta, on see tegelikult täielikult teie enda oma kontroll.
Ryanil on bakalaureuse kraad elektrotehnika alal. Ta on töötanud 13 aastat automatiseerimise alal, 5 aastat IT alal ja on nüüd rakenduste insener. MakeUseOfi endine tegevtoimetaja, ta on rääkinud andmete visualiseerimise riiklikel konverentsidel ja teda on kajastatud üleriigilises televisioonis ja raadios.