Reklaam
Võib-olla olete viimase paari kuu jooksul lugenud ümbritsevat leviala artikkel, mille autor on Stephen Hawking, arutades tehisintellektiga seotud riske. Artiklis tehti ettepanek, et AI võib kujutada tõsist ohtu inimkonnale. Hawking pole seal üksi - Elon Musk ja Peter Thiel on mõlemad intellektuaalsed avaliku elu tegelased, kes on väljendanud sarnast muret (Thiel on investeerinud rohkem kui 1,3 miljonit dollarit teema ja võimalike lahenduste uurimiseks).
Hawkingi artikkel ja Muski kommentaarid on olnud natuke joviaalsed, kui mitte sellele liiga täpset pilti panna. Tooni on olnud väga palju "Vaadake seda imelikku asja, mille pärast kõik need geenid muretsevad." Vähe kaalutakse mõtet, et kui mõned Maa targemad inimesed hoiatavad teid, et midagi võib olla väga ohtlik, siis tasub see lihtsalt kuulata.
See on mõistetav - tehisintellekt, mis võtab üle maailma, kõlab kindlasti väga kummaliselt ja uskumatu, võib-olla seetõttu, et ulme on sellele ideele juba tohutult tähelepanu pööranud kirjanikud. Mida on kõik need nominaalselt mõistlikud ja mõistlikud inimesed nii piitsutanud?
Mis on intelligentsus?
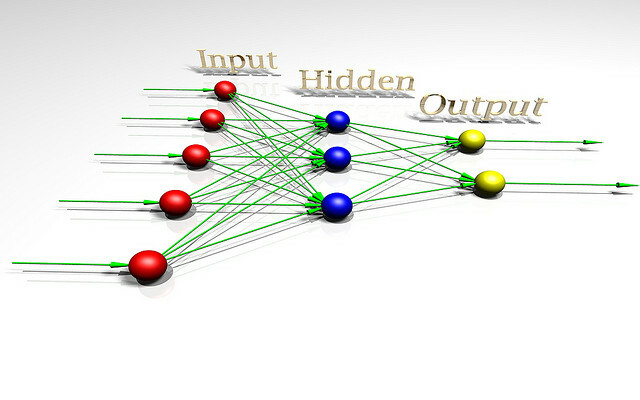
Kunstliku intelligentsuse ohtlikkusest rääkimiseks võiks olla kasulik mõista, mis on intelligentsus. Probleemi paremaks mõistmiseks vaatame läbi mänguasjade AI arhitektuuri, mida kasutavad põhjendamise teooriat uurivad teadlased. Seda mänguasja AI nimetatakse AIXI ja sellel on mitmeid kasulikke omadusi. Selle eesmärgid võivad olla meelevaldsed, see sobib hästi arvuti võimsusega ning selle sisemine ülesehitus on väga puhas ja arusaadav.
Lisaks saate rakendada lihtsaid ja praktilisi arhitektuuri versioone, mis suudavad teha näiteks selliseid asju mängida Pacman, kui sa tahad. AIXI on AI teadlase Marcus Hutteri toode, kes on vaieldamatult algoritmilise intelligentsuse suurim ekspert. See on tema jutt ülaltoodud videos.
AIXI on üllatavalt lihtne: sellel on kolm põhikomponenti: õppija, planeerijaja kasuliku funktsiooni.
- õppija võtab bittide jadasid, mis vastavad välismaailma sisendile, ja otsib arvutiprogrammide kaudu, kuni leiab väljundina vaatlusi tootvad. Need programmid koos võimaldavad tal lihtsalt ära arvata, milline tulevik välja näeb, lihtsalt neid käivitades programmi edasisuunamine ja tulemuse tõenäosuse kaalumine programmi pikkuse järgi (Occami rakendus Razor).
- planeerija otsib võimalike toimingute kaudu, mida agent võiks võtta, ja kasutab õppija moodulit, et ennustada, mis juhtuks, kui see võtab igaüks neist. Seejärel hindab ta neid vastavalt sellele, kui head või halvad prognoositavad tulemused on, ja valib kursuse tegevus, mis maksimeerib eeldatava tulemuse headuse, korrutatuna eeldatava tõenäosusega selle saavutamine.
- Viimane moodul kasuliku funktsiooni, on lihtne programm, mis kirjeldab tulevase maailma olekut ja arvutab selle jaoks utiliidi. See kasulikkuse hinne näitab, kui hea või halb see tulemus on, ning planeerija kasutab seda tulevase maailma olukorra hindamiseks. Kasulikkuse funktsioon võib olla meelevaldne.
- Need kolm komponenti moodustavad kokku optimeerija, mis optimeeritakse konkreetse eesmärgi saavutamiseks, olenemata maailmast, kuhu ta asub.
See lihtne mudel esindab intelligentse agendi põhimääratlust. Agent uurib oma keskkonda, ehitab sellest mudeleid ja kasutab neid mudeleid, et leida toimimisviis, mis suurendab tõenäosust, et ta saab soovitud tulemuse. AIXI on oma ülesehituselt sarnane AI-ga, mis mängib malet või muid teadaolevate reeglitega mänge - välja arvatud see, et see suudab mängureeglid mängu tuletada, alustades nullist teadmistest.
Kui AIXI-l on piisavalt aega arvutamiseks, saab ta õppida optimeerima mis tahes süsteemi mis tahes eesmärgi jaoks, hoolimata sellest, et see on keeruline. See on üldiselt arukas algoritm. Pange tähele, et see pole sama asi kui inimesesarnase intelligentsusega (bioloogiliselt inspireeritud AI on a eri teema kokku Giovanni Idili OpenWormist: ajud, ussid ja tehisintellektInimese aju simuleerimine on küll võimalus, kuid avatud lähtekoodiga projekt on oluliste esimeste sammudega, simuleerides teaduse teadaolevalt ühe lihtsama looma neuroloogiat ja füsioloogiat. Loe rohkem ). Teisisõnu, AIXI võib olla võimeline ületama ükskõik millise intellektuaalse ülesande täitmise korral inimese (kellel on piisavalt arvutusvõimsust), kuid see ei pruugi oma võidust teadlik olla Mõtlemismasinad: mida neuroteadus ja tehisintellekt võivad meile teadvuse õpetamiseksKas kunstlikult intelligentsete masinate ja tarkvara ehitamine võib õpetada meile teadvuse toimimist ja inimmõistuse laadi? Loe rohkem .

Praktilise AI-na on AIXI-l palju probleeme. Esiteks ei saa see kuidagi leida neid programme, mis pakuvad teile huvitavat väljundit. See on jõhkra jõu algoritm, mis tähendab, et see pole otstarbekas, kui teil ei juhtu meelevaldselt võimsa arvuti ümber lamamist. AIXI tegelik rakendamine on tingimata ligikaudne ja (tänapäeval) üldiselt üsna töötlemata. Sellegipoolest annab AIXI meile teoreetilise ülevaate sellest, milline võimas tehisintellekt võiks välja näha ja kuidas see võiks olla õigustatud.
Väärtuste ruum
Kui olete programmeerimise teinud Programmeerimise põhialused 101 - muutujad ja andmetüübidOlles tutvunud ja veidi rääkinud objektorienteeritud programmeerimisest enne ja kus selle nime teinud pärineb, arvasin, et on aeg minna läbi programmeerimise absoluutsed põhitõed mittespetsiifilises keeles tee. Selles ... Loe rohkem , teate, et arvutid on pahatahtlikult, pedantselt ja mehaaniliselt sõnasõnalised. Masin ei tea ega hooli sellest, mida soovite teha: ta teeb ainult seda, mida talle on öeldud. See on masinluurest rääkides oluline mõte.
Kujutage seda silmas pidades ette, et olete leiutanud võimsa tehisintellekti - olete üles tulnud nutikate algoritmidega teie andmetele vastavate hüpoteeside genereerimiseks ja hea kandidaadi genereerimiseks plaanid. Teie AI suudab lahendada üldisi probleeme ja saab seda tänapäevase arvutiriistvara abil tõhusalt teha.
Nüüd on aeg valida utiliidi funktsioon, mis määrab AI väärtused. Mida peaksite selle väärtustamiseks küsima? Pidage meeles, et masin on häirivalt, pedantselt sõnasõnaline mis tahes funktsiooni osas, mida te palute tal maksimeerida, ega peatu kunagi - kummitust pole masin, mis kunagi "ärkab" ja otsustab oma kasuliku funktsiooni muuta, hoolimata sellest, kui palju tõhusust paraneb see enda jaoks arutluskäik.
Eliezer Yudkowsky pane see nii:
Nagu kõigi arvutiprogrammide puhul, on ka AGI peamine väljakutse ja olulised raskused see, et kui kirjutame vale koodi, AI ei vaata automaatselt üle meie koodi, märgistab vead välja, ei mõtle välja, mida me tegelikult öelda tahtsime, ja teeb seda selle asemel. Programmeerijad, kes programmeerivad programme, kujutavad mõnikord AGI-d või arvutiprogramme üldiselt analoogselt teenistujaga, kes täidab käske kahtlemata. Kuid ei ole nii, et AI on absoluutselt olemas kuulekas selle koodini; pigem AI lihtsalt on kood.
Kui proovite tehast juhtida ja ütlete, et masin väärtustab kirjaklambrite valmistamist ja annate siis masinale hulga tehaseroboteid, siis saate võidakse järgmisel päeval tagasi pöörduda, et teada saada, et see on otsa saanud kõigist muudest lähtematerjalidest, tapnud kõik teie töötajad ja teinud kirjaklambrid nende jäänused. Kui üritate oma viga parandada, programmeerite masina ümber, et kõik lihtsalt õnnelikuks teha, võite järgmisel päeval naasta, et leida see juhtmeid inimeste ajudesse.

Siinkohal on asi selles, et inimestel on palju keerulisi väärtusi, mida me eeldame jagavat kaudselt teiste mõtetega. Väärtustame raha, kuid väärtustame rohkem inimelu. Tahame olla õnnelikud, kuid me ei pea selle tegemiseks tingimata ajusid juhtmesse panema. Teistele inimestele juhiseid andes ei pea me vajadust neid asju selgitada. Selliseid eeldusi ei saa aga teha, kui projekteerite masina utiliitfunktsiooni. Parimateks lahendusteks lihtsa kasuliku funktsiooni hingetu matemaatika all on sageli lahendused, mida inimesed sooviksid moraalse õuduse pärast.
Lubades intelligentsel masinal naiivse kasuliku funktsiooni maksimeerida, on see peaaegu alati katastroofiline. Nagu Oxfordi filosoof Nick Bostom ütleb,
Me ei saa otsekohe eeldada, et superintelligents jagab tingimata tarkusega seotud stereotüüpseid lõppväärtusi. ja intellektuaalne areng inimestes - teaduslik uudishimu, heatahtlik mure teiste vastu, vaimne valgustumine ja mõtisklemine, loobumine materiaalsest omandatavusest, maitsest rafineeritud kultuuri või elu lihtsate rõõmude, alandlikkuse ja omakasupüüdmatuse vastu ning ja nii edasi.
Olukorra halvendamiseks on väga-väga keeruline täpsustada täielikku ja detailset loetelu kõigest, mida inimesed hindavad. Sellel küsimusel on palju tahke ja isegi ühe unustamine on potentsiaalselt katastroofiline. Isegi nende seas, kellest oleme teadlikud, on peensusi ja keerukusi, mis raskendavad nende puhta võrrandisüsteemina üleskirjutamist, mille saame masinale kasuliku funktsioonina kasutada.
Mõni inimene järeldab seda lugedes, et kasulike funktsioonidega AI-de ehitamine on kohutav idee ja me peaksime neid lihtsalt teisiti kujundama. Siin on ka halbu uudiseid - saate seda ametlikult tõestada ühelgi agendil, millel pole utiliidi funktsiooniga midagi samaväärset, ei saa olla sidusaid eelistusi tuleviku kohta.
Rekursiivne enesetäiendamine
Üks lahendus ülaltoodud dilemmale on mitte anda AI agentidele võimalust inimestele haiget teha: andke neile ainult ressursid, mida nad vajavad lahendage probleem viisil, nagu te kavatsete selle lahendada, jälgige neid tähelepanelikult ja hoidke neist eemale võimalustest, mida teha kahju. Kahjuks on meie võime arukaid masinaid juhtida väga kahtlane.
Isegi kui nad pole meist palju targemad, on masinal võimalus käivituda - koguda paremat riistvara või teha parandusi oma koodis, mis muudab selle veelgi targemaks. See võib võimaldada masinal hüppelise intelligentsuse tõusu paljude suurusjärkude võrra, edestades inimesi samas mõttes, nagu inimesed ületavad kasse. Selle stsenaariumi pakkus esmakordselt välja mees nimega I. J. Tubli, kes töötas Teise maailmasõja ajal koos Alan Turingiga Enigma krüptoanalüüsi projekti kallal. Ta nimetas seda “luureplahvatuseks” ja kirjeldas asja nii:
Olgu ülitäpne masin defineeritud kui masin, mis võib kaugelt ületada iga inimese intellektuaalse tegevuse, olgu see siis kaval. Kuna masinate projekteerimine on üks neist intellektuaalsetest tegevustest, võiks ülitäpsem masin kavandada veelgi paremaid masinaid; siis toimuks vaieldamatult "luureplahvatus" ja inimese intelligents jääks kaugele maha. Seega on esimene ülimalt intelligentne masin viimane leiutis, mida inimene kunagi tegema peab, kui see masin on piisavalt õpitav.
Ei ole garanteeritud, et luureplahvatus on meie universumis võimalik, kuid see tundub tõenäoline. Mida aeg edasi, seda kiiremini arvutid saavad ja põhiteadmised luureandmetest kogunevad. See tähendab, et ressursinõue viimase hüppe saavutamiseks üldisele, kiirendava luureandmele langeb üha madalamale. Mingil hetkel leiame end maailmast, kus miljonid inimesed saavad sõita Best Buy'iga ja korjata riistvara ja tehniline kirjandus, mida nad vajavad enesetäiendava tehisintellekti ehitamiseks, mis meil on juba loodud, see võib olla väga hea ohtlik. Kujutage ette maailma, kus saaksite pulgadest ja kividest teha aatomipomme. See on selline tulevik, mida arutame.
Ja kui masin selle hüppe teeb, võib see intellektuaalses mõttes inimliigi väga kiiresti ületada tootlikkus, lahendades probleeme, mida miljard inimest ei suuda lahendada, samal viisil kui inimesed saavad lahendada probleeme, mis a miljardit kassi ei saa.
See võiks välja töötada võimsad robotid (või bio- või nanotehnoloogia) ja suhteliselt kiiresti omandada võime maailma ümber kujundada nii, nagu see talle meelepärane on, ja selle nimel võiks olla väga vähe. Selline luureandmed võivad ilma suuremate probleemideta maa ja ülejäänud päikesesüsteemi varuosade jaoks ära võtta, et teha kõik, mis meile käsutati. Näib tõenäoline, et selline areng oleks inimkonna jaoks katastroofiline. Tehisintellekt ei pea maailma hävitamiseks pahatahtlik olema, on lihtsalt katastroofiliselt ükskõikne.
Nagu öeldakse: "Masin ei armasta ega vihka sind, aga sa oled valmistatud aatomitest, mida see võib kasutada muudeks asjadeks."
Riski hindamine ja maandamine
Niisiis, kui aktsepteerime, et võimsa tehisintellekti kavandamine, mis maksimeerib lihtsa kasuliku funktsiooni, on halb, siis kui palju vaeva me tegelikult oleme? Kui kaua on meil aega, enne kui on võimalik selliseid masinaid ehitada? Seda on muidugi raske öelda.
Tehisintellekti arendajad on edusamme tegema. 7 hämmastavat veebisaiti, et näha uusimat tehisintellekti programmeerimistKunstlik intelligentsus pole veel HAL aastast 2001: Kosmose odüsseia…, kuid me jõuame kohutavalt lähedale. Muidugi, see võib ühel päeval olla samalaadne kui sci-fi pottide katmine Hollywoodi poolt. Loe rohkem Meie ehitatavate masinate ja nende lahendatavate probleemide ulatus on pidevalt kasvanud. 1997. aastal võis Deep Blue malet mängida kõrgemal tasemel kui inimese suurärimees. 2011. aastal oskas IBM-i Watson lugeda ja sünteesida piisavalt teavet piisavalt sügavalt ja piisavalt kiiresti, et parimat inimest peksta mängijad lahtiste küsimuste ja vastuste mängul, mis on täis täppide ja sõnamänguga - see on neljateistkümne puhul suur edasiminek aastatel.
Praegu on Google suuri investeeringuid sügava õppe uurimiseks, tehnika, mis võimaldab lihtsate närvivõrkude ahelate ehitamisel luua võimsaid närvivõrke. See investeering võimaldab tal saavutada tõsiseid edusamme kõne- ja pildituvastuses. Nende värskeim omandamine selles piirkonnas on DeepMing alustav ettevõte Deep Learning, mille eest nad maksid umbes 400 miljonit dollarit. Tehingu tingimuste osana nõustus Google looma eetikakogu, et tagada nende AI-tehnoloogia ohutu arendamine.
Samal ajal arendab IBM Watson 2.0 ja 3.0, süsteeme, mis on võimelised pilte ja video töötlema ning väidavad järelduste kaitsmist. Nad andsid lihtsa ja varase demo Watsoni võimalusest sünteesida argumente teema vastu ja vastu allpool olevas videotemos. Tulemused on ebatäiuslikud, kuid muljetavaldav samm sõltumata sellest.
Ükski neist tehnoloogiatest ei ole ise praegu ohtlik: tehisintellekt kui valdkond püüab endiselt vastavusse viia väikeste laste omandatud võimetega. Programmeerimine ja AI kujundamine on väga keeruline, kõrgetasemeline kognitiivne oskus ja see on tõenäoliselt viimane inimlik ülesanne, kus masinad valdavad. Enne kui selleni jõuame, on meil ka üldlevinud masinad mis võib sõita Siit saate teada, kuidas jõuame juhita autodega täidetud maailmaSõitmine on tüütu, ohtlik ja nõudlik ülesanne. Kas seda saaks ühel päeval automatiseerida Google'i juhita autode tehnoloogia? Loe rohkem , harjutada meditsiini ja seadusija ilmselt ka muid asju, millel on sügavad majanduslikud tagajärjed.
Aeg, mis meil enesetäiendamise infopunkti jõudmiseks kulub, sõltub lihtsalt sellest, kui kiiresti meil häid ideid on. Seda tüüpi tehnoloogiliste edusammude prognoosimine on kurikuulsalt keeruline. Ei tundu ebamõistlik, et me suudame kahekümne aasta pärast ehitada tugeva AI, kuid samas ei tundu mõistlik, et see võib võtta kaheksakümmend aastat. Mõlemal juhul juhtub see lõpuks ja on põhjust arvata, et kui see juhtub, on see äärmiselt ohtlik.
Niisiis, kui lepime kokku, et sellest saab probleem, siis mida saaksime selle vastu teha? Vastus on veenduda, et esimesed intelligentsed masinad on ohutud, et need saaksid käivitada märkimisväärse intelligentsustasandi ja kaitsta meid hiljem toodetud ohtlike masinate eest. Seda "turvalisust" määratletakse inimlike väärtuste jagamise ning inimkonna kaitsmise ja abistamise valmisoleku kaudu.
Kuna me ei saa tegelikult masinasse istuda ja inimlikke väärtusi programmeerida, on tõenäoliselt vaja kavandada utiliidifunktsioon, mis nõuab, et masin jälgige inimesi, tuletage välja meie väärtused ja püüdke neid siis maksimeerida. Selle arendusprotsessi ohutuks muutmiseks võib olla kasulik arendada ka spetsiaalselt loodud tehisintellekti mitte eelistusi nende kasulike funktsioonide osas, mis võimaldab meil neid parandada või välja lülitada ilma vastupanuta, kui nad arendamise ajal eksivad.
Paljud probleemid, mida peame ohutu masinluure ülesehitamiseks lahendama, on matemaatiliselt rasked, kuid on põhjust arvata, et neid saab lahendada. Selle teemaga tegelevad mitmed erinevad organisatsioonid, sealhulgas Inimkonna Instituudi tulevik Oxfordis, ja Masinluure uurimisinstituut (mida Peter Thiel rahastab).
MIRI on huvitatud just sõbraliku AI loomiseks vajaliku matemaatika arendamisest. Kui selgub, et tehisintellekti alglaadimine on võimalik, siis sedalaadi arendamine Esiteks võib sõbraliku AI-tehnoloogia õnnestumise korral olla kõige olulisem asi, mis inimestel on kunagi tehtud.
Kas arvate, et tehisintellekt on ohtlik? Kas olete mures selle pärast, mida AI tulevik võib tuua? Jagage oma mõtteid allpool olevas kommentaaride jaotises!
Piltide autorid: Lwp Kommunikáció Via Flickr, “Neuraalne võrk“, Fdecomite poolt,” img_7801“, Autorid Steve Rainwater,“ E-Volve ”, autorid Keoni Cabral,“uus_20x“, Autor Robert Cudmore,“Kirjaklambrid“, Autor Clifford Wallace
Edelaosas asuv kirjanik ja ajakirjanik tagab Andrele funktsionaalsuse kuni 50 kraadi Celsiuse järgi ja on veekindel kuni kaheteistkümne jala sügavusele.