Reklaam
Kui sa hallata veebisaiti 10 viisi väikese ja lihtsa veebisaidi loomiseks ilma ülepaisutamisetaWordPress võib olla liiga suur osa. Nagu need muud suurepärased teenused tõestavad, pole WordPress veebisaitide loomine kõige lõpp ja lõpp. Kui soovite lihtsamaid lahendusi, on teil palju erinevaid. Loe rohkem , olete ilmselt kuulnud faili robots.txt kohta (või „robotite välistamise standardit“). Olenemata sellest, kas teil on või mitte, on aeg sellest teada saada, sest see lihtne tekstifail on teie saidi oluline osa. See võib tunduda tähtsusetu, kuid võite olla üllatunud, kui oluline see on.
Vaatame üle, mis on fail robots.txt, mida see teeb ja kuidas seda oma saidil õigesti seadistada.
Mis on fail robots.txt?
Faili robots.txt toimimise mõistmiseks peate teadma natuke otsingumootorite kohta Kuidas otsimootorid töötavad?Paljudele inimestele on Google IS Internet. See on vaieldamatult kõige olulisem leiutis alates Internetist endast. Ja kuigi otsingumootorid on pärast seda palju muutunud, on põhimõtted endiselt samad. Loe rohkem
. Lühike versioon on see, et nad saadavad välja indekseerijad - programmid, mis otsivad teavet Internetis. Seejärel salvestavad nad osa sellest teabest, et nad saaksid inimesi hiljem selle juurde suunata.Need robotid, tuntud ka kui „robotid” või „ämblikud”, leiavad lehti miljarditelt veebisaitidelt. Otsimootorid annavad neile juhiseid, kuhu minna, kuid ka üksikud veebisaidid saavad robotitega suhelda ja öelda, milliseid lehti nad peaksid vaatama.
Enamasti teevad nad tegelikult vastupidist ja ütlevad neile, milliseid lehti nad teevad ei peaks vaadake. Sellised asjad nagu halduslehed, taustaportaalid, kategooria- ja sildilehed ning muud, mida saidiomanikud ei soovi, et otsingumootorites kuvataks. Need lehed on kasutajatele endiselt nähtavad ja neile pääsevad ligi kõik, kellel on luba (sageli on see kõik).
Kuid öeldes robotitele, et nad ei peaks mõnda lehte indekseerima, teeb fail robots.txt kõigile teene. Kui otsisite otsingumootorist otsingumootorit „MakeUseOf”, kas soovite, et meie administratiivlehed kuvaksid edetabeli kõrgel kohal? Ei. See ei teeks kellelegi midagi head, seetõttu käsime otsimootoritel neid mitte kuvada. Seda saab kasutada ka selleks, et otsimootorid ei kontrolliks lehti, mis ei pruugi aidata teil teie saiti otsingutulemustes klassifitseerida.
Lühidalt öeldes: robots.txt ütleb veebianduritele, mida teha.
Kas indeksoijat saavad robotit.txt ignoreerida?
Kas indekseerijad eiravad kunagi faile robots.txt? Jah. Tegelikult paljud indekseerijad teha Ignoreeri seda. Üldiselt ei ole need indekseerijad pärit usaldusväärsetest otsingumootoritest. Nad pärinevad rämpspostitajatest, e-posti koristajatest ja muud tüüpi automatiseeritud robotid Kuidas luua põhiline veebi indeksoija veebisaidilt teabe kogumiseksKas olete kunagi tahtnud veebisaidilt teavet lüüa? Siit saate teada, kuidas kirjutada indeksoijat veebisaidil navigeerimiseks ja vajaliku ekstraheerimiseks. Loe rohkem mis rändlesid Internetis. Oluline on seda meeles pidada - roboti välistamise standardi kasutamine robotite käsitsemiseks eemale hoidmiseks pole tõhus turvameede. Tegelikult võivad mõned robotid algus lehtedega, mille peale kästud neil mitte minna.
Otsimootorid toimivad aga nii, nagu teie fail robots.txt ütleb, kui see on õigesti vormindatud.
Kuidas kirjutada faili robots.txt
On mõned erinevad osad, mis lähevad roboti välistamise standardfaili. Ma jagan nad siin igaüks eraldi.
Kasutajaagendi deklaratsioon
Enne kui ütlete robotile, milliseid lehti ta ei peaks vaatama, peate täpsustama, millise robotiga te räägite. Enamasti kasutate lihtsat deklaratsiooni, mis tähendab “kõik robotid”. See näeb välja selline:
Kasutaja agent: *Tärn tähistab sõna "kõik robotid". Võite siiski täpsustada teatud robotite lehed. Selleks peate teadma boti nime, mille jaoks juhiseid koostate. See võib välja näha järgmine:
Kasutajaagent: Googlebot. [indekseerimata lehtede loetelu] Kasutajaagent: Googlebot-Image / 1.0. [indekseerimata lehtede loetelu] Kasutajaagent: Bingbot. [indekseerimata lehtede loetelu]Ja nii edasi. Kui leiate boti, mida te ei soovi oma saidil üldse roomata, saate selle ka täpsustada.
Kasutajaagentide nimede leidmiseks tutvuge saidiga useragentstring.com [pole enam saadaval].
Lehtede keelamine
See on teie roboti välistamise faili põhiosa. Lihtsa deklaratsiooniga käsite robotil või robotirühmal teatud lehti mitte indekseerida. Süntaks on lihtne. Siit saate teada, kuidas keelata juurdepääsu kõigele oma saidi „administraatori” kataloogis:
Keela: / admin /See rida takistaks robotitel indekseerimast teie veebisaiti.com/admin, yoursite.com/admin/login, yoursite.com/admin/files/secret.html ja kõike muud, mis kuulub administraatorikataloogi.
Ühe lehe keelamiseks täpsustage see keelamisreal:
Keela: /public/exception.htmlNüüd ei eemaldata lehte „erand”, vaid kõik muu, mis asub avalikus kaustas.
Mitme kataloogi või lehe kaasamiseks loetlege need lihtsalt järgmistel ridadel:
Keela: / privaatne / Keela: / admin / Keela: / cgi-bin / Keela: / temp /Need neli rida kehtivad ükskõik kumma kasutajaagendi kohta, mille määrasite jaotise ülaosas.
Kui soovite, et robotid ei vaataks ühtegi teie saidi lehte, kasutage järgmist.
Keela: /Erinevate standardite seadmine robotitele
Nagu me eespool nägime, saate erinevate robotite jaoks täpsustada teatud lehed. Kaks eelmist elementi ühendades näeb välja järgmine:
Kasutajaagent: googlebot. Keela: / admin / Keela: / privaatne / Kasutaja-agent: bingbot. Keela: / admin / Keela: / privaatne / Keela: / salajane /Jaod „admin” ja „privaat” on Google'is ja Bingis nähtamatud, kuid Google näeb „salajast” kataloogi, samas kui Bing seda ei tee.
Tärnide kasutajaagenti abil saate määrata kõigi robotite üldreeglid ja anda ka järgmistes sektsioonides robotitele konkreetsed juhised.
Kõike kokku panema
Ülaltoodud teadmistega saate kirjutada täieliku faili robots.txt. Lihtsalt vallandage oma lemmiktekstiredaktor (meie oleme Sublime fännid 11 ülevust teksti näpunäiteid produktiivsuse ja kiirema töövoo jaoksSublime Text on mitmekülgne tekstiredaktor ja paljude programmeerijate jaoks kullastandard. Meie näpunäited keskenduvad tõhusale kodeerimisele, kuid tavakasutajad hindavad kiirklahve. Loe rohkem siin)) ja hakake robotitele teatama, et nad pole teie saidi teatavates osades teretulnud.
Kui soovite näha faili robots.txt näidet, minge suvalisele saidile ja lisage lõppu „/robots.txt”. Siin on osa hiiglaslike jalgrataste failist robots.txt:
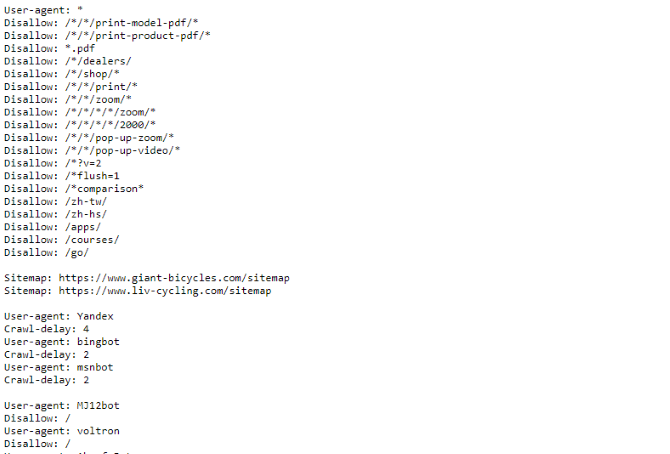
Nagu näete, on üsna palju lehti, mida nad ei soovi otsingumootorites kuvada. Nad on lisanud ka mõned asjad, millest me pole veel rääkinud. Vaatame, mida veel saate oma roboti välistamise failis teha.
Saidikaardi leidmine
Kui teie fail robots.txt ütleb robotitele, kus? mitte minna, oma saidikaart teeb vastupidist XML-saidiplaani loomine 4 lihtsa sammunaSaidikaarte on kahte tüüpi - HTML-leht või XML-fail. HTML-saidiplaan on üks leht, mis näitab külastajatele kõiki veebisaidi lehti ja sisaldab tavaliselt linke nendele ... Loe rohkem ja aitab neil leida, mida nad otsivad. Ja kuigi otsimootorid juba teavad, kus teie saidiplaan asub, ei ole valus neile uuesti teada anda.
Saidikaardi asukoha deklareerimine on lihtne:
Saidikaart: [saidikaardi URL]See selleks.
Meie oma failis robots.txt näeb see välja järgmine:
Saidikaart: //www.makeuseof.com/sitemap_index.xmlSelles on kõik olemas.
Indekseerimise viivituse seadmine
Indekseerimise viivituse direktiiv ütleb teatud otsingumootoritele, kui sageli nad saavad teie saidi lehte indekseerida. Seda mõõdetakse sekundites, ehkki mõned otsingumootorid tõlgendavad seda pisut erinevalt. Mõni näeb indekseerimise viivitust 5-kordselt, öeldes, et nad ootavad järgmise indeksi käivitamiseks pärast iga indekseerimist viis sekundit. Teised tõlgendavad seda juhisena, mille kohaselt tuleb indekseerida vaid üks leht iga viie sekundi tagant.
Miks ütleksid robotile, et ta ei roomaks nii palju kui võimalik? Et säilitada ribalaiust 4 viisi, kuidas Windows 10 raiskab teie Interneti-ribalaiustKas Windows 10 raiskab teie Interneti-ribalaiust? Siit saate teada, kuidas kontrollida ja mida saate selle peatamiseks teha. Loe rohkem . Kui teie server üritab liiklusega sammu pidada, võiksite käivitada indekseerimise viivituse. Üldiselt ei pea enamik inimesi selle pärast muretsema. Suured tiheda liiklusega saidid võivad siiski soovida natuke katsetada.
Kaheksa sekundilise indekseerimise viivituse määramiseks toimige järgmiselt.
Indekseerimise viivitus: 8See selleks. Kõik otsingumootorid ei järgi teie direktiivi. Kuid küsida pole valus. Sarnaselt lehtede keelamisega saate konkreetsetele otsingumootoritele seada erinevad indekseerimise viivitused.
Teie faili robots.txt üleslaadimine
Kui olete kõik faili juhised seadistanud, saate selle oma saidile üles laadida. Veenduge, et see oleks lihttekstifail ja nimeks robots.txt. Seejärel laadige see oma saidile üles, nii et selle leiate veebisaidilt yoursite.com/robots.txt.
Kui kasutate a sisuhaldussüsteem 10 kõige populaarsemat veebisisu haldussüsteemiKäsitsi kodeeritud HTML-lehtede ja CSS-i omandamise päevad on juba ammu möödas. Installige sisuhaldussüsteem (CMS) ja mõne minuti jooksul saate omada veebisaiti, mida maailmale jagada. Loe rohkem nagu WordPress, peate selle saavutamiseks tõenäoliselt leidma konkreetse tee. Kuna see erineb sisuhaldussüsteemides erinevalt, peate tutvuma oma süsteemi dokumentatsiooniga.
Mõnel süsteemil võivad olla ka veebiliidesed teie faili üleslaadimiseks. Nende jaoks lihtsalt kopeerige ja kleepige eelmistes sammudes loodud fail.
Ärge unustage oma faili värskendada
Viimane nõuanne, mida annan, on aeg-ajalt teie roboti välistamise fail üle vaadata. Teie sait muutub ja peate võib-olla tegema mõned muudatused. Kui märkate oma otsingumootori liikluses kummalist muutust, on hea mõte vaadata ka seda faili. Samuti on võimalik, et standardmärge võib tulevikus muutuda. Nagu kõik muu teie saidil, tasub seda vaadata aeg-ajalt.
Millised lehed välistate indekseerijad oma saidilt? Kas olete märganud mingeid erinevusi otsimootorite liikluses? Jagage oma nõuandeid ja kommentaare allpool!
Dann on sisestrateegia ja turunduskonsultant, kes aitab ettevõtetel nõudlust tekitada ja viib. Samuti ajaveeb ta veebiaadressil dannalbright.com strateegia- ja sisuturunduse kohta.


